Интерфейсы и API
Интерфейсы и API
На этой неделе мы поговорим об API — Application Programming Interface. Ключевое слово тут Interface. Что такое интерфейс? Это что-то такое, посредством чего мы взаимодействуем с системой.
У нас есть какая-то сложная система и простой интерфейс, который позволяет взаимодействовать с этой системой, не задумываясь о её внутреннем устройстве.
Пример: автомобиль. Внутри он устроен очень сложно, но тебе не нужно разбираться в его внутреннем устройстве, достаточно лишь крутить руль и нажимать на педали. Руль и педали в данном случае — это интерфейс управления автомобилем.
Ещё пример: человек. Мы можем взаимодействовать с другим человеком посредством голосового интерфейса. Или языком жестов. Или как-то ещё.
В общем, понятие номер один — интерфейс это средство взаимодействия. С этим разобрались. Идём дальше.
Второе: интерфейс должен быть как-то стандартизирован. Чтобы взаимодействовать с другим человеком голосом, ты должен изучить этот стандарт — в данном случае выучить язык.
У сложных компьютерных программ тоже есть свои стандартизированные интерфейсы, так называемые API, которые позволяют общаться с ними на одном языке. Например, API есть у всех популярных сервисов, таких как ВКонтакте, Telegram, даже у GitHub.
У API тоже есть свои стандарты, мы сейчас обсудим самый популярный из них — REST API.
REST API и как работает интернет
Совсем чуточку истории. Рой Филдинг, которого можно назвать одним из создателей интернета, в своей диссертации описал стандарт передачи данных через протокол HTTP: https://www.ics.uci.edu/~fielding/pubs/dissertation/rest_arch_style.htm
Читать эту диссертацию не обязательно, я постараюсь пересказать её своими словами. Но для начала нужно понять несколько базовых вещей. Начнем с того, как работает интернет.
Если максимально упрощать, то примерно так:
По всему миру есть очень много устройств, которые объединены в сеть. Глобальную сеть. По всему миру под землёй и на дне океана проложены огромные кабели, они соединяют континенты, страны и города через огромные дата-центры. В любом крупном городе есть дата-центр, который прокладывает чуть менее толстый кабель к интернет-провайдеру, в свою очередь интернет-провайдер прокладывает ещё менее толстый кабель в отдельные районы города и к твоему дому, чтобы ты мог пользоваться этой сетью. Это очень упрощено, но суть такова — все компьютеры связаны огромной сетью.
В этой сети между собой взаимодействуют устройства. Условно эти устройства можно разделить на две категории: клиент и сервер. Клиент получает информацию. Сервер раздаёт информацию. Когда ты со своего смартфона заходишь на сайт прогноза погоды, твой браузер на смартфоне в данном случае клиент, а сервер прогноза погоды...ну, понятно.
Клиент и сервер общаются посредством запросов. Клиент посылает серверу запрос "хочу получить данные", сервер ему эти данные возвращает (если всё окей).
У клиента и сервера есть свои уникальные IP-адреса.
IP-адреса сложно держать в голове, поэтому существует специальная система DNS (Domain Name System) — система доменных имён. Она позволяет зарегистрировать для ip-адреса сервера какой-нибудь понятный домен, например python101.online вместо 185.199.108.153. Так гораздо удобнее.
Запросы чаще всего осуществляются по протоколу HTTP (Hypertext Transfer Protocol).
Допустим, ты, как клиент, хочешь открыть страницу https://python101.online. Ты вводишь адрес (так называемый URL, Uniform Resource Locator) в браузере, браузер спрашивает у системы DNS, какой IP-адрес скрывается за этим доменом, совершает запрос на этот IP-адрес, ему возвращается результат. Результат может быть в формате HTML (язык разметки, который позволяет браузеру отрисовать страницу) или в любом другом, например в формате картинки или чистых данных. Подробнее об этом можно почитать здесь: https://habr.com/ru/company/htmlacademy/blog/254825/
Но это всё про браузер. А когда возникает необходимость передавать данные в чистом виде, например, такие как прогноз погоды, нам не нужно получать HTML-страницу, нам нужно только название города и температура в этом городе. Для работы с такими кейсами в том числе и был придумана стандартизация REST, о которой было сказано выше.
REST API — это правила для передачи данных по сети интернет, стандарт, по которому общаются разные сервисы.
Сейчас мы будем делать HTTP-запросы прямо из кода на Питоне. И в этом нам поможет библиотека requests: ****https://requests.readthedocs.io/en/master/
HTTP-запросы из кода. Библиотека requests
Чтобы совершать HTTP-запросы из кода на Питоне существует встроенная библиотека urllib: https://docs.python.org/3/library/urllib.html
Но так сложилось, что более удобный аналог, который является оберткой для встроенной библиотекой: https://requests.readthedocs.io/en/master/ Мы будем использовать его.
Создай файл spam.py:
import requests
response = requests.get('https://python101.online')
print(response.text)
В ответ придёт HTML-код страницы сайта нашего курса:
Этот HTML-код предназначен для браузера и он используется для отрисовки страницы.
В переменной response у нас теперь лежит объект ответа, мы вызвали у него метод .text и получили HTML. Но у этого объекта есть ещё много интересных методов, например:
response.status_code # вернёт статус-код ответа
response.raise_for_status # метод для проверки успешности запроса
response.encoding # кодировка
response.url # адрес URL
Когда мы хотим работать в коде со структурированными данными, нам не подходит формат HTML. Есть несколько популярных форматов для передачи данных по сети, мы рассмотрим формат JSON.
Формат JSON
Формат JSON похож на обычный словарь в Питоне. Есть ключ и значение, есть вложенность. Разница в том, что JSON более стандартизирован и строг, например в нём можно использовать только двойные кавычки. Подробнее здесь: https://www.json.org/json-ru.html
Например, вот так выглядит запрос к сервису API https://superheroapi.com по запросу Batman:
{
"response": "success",
"results-for": "batman",
"results": [
{
"id": "69",
"name": "Batman",
"powerstats": {
"intelligence": "81",
"strength": "40",
"speed": "29",
"durability": "55",
"power": "63",
"combat": "90"
},
"biography": {
"full-name": "Terry McGinnis",
"alter-egos": "No alter egos found.",
"aliases": [
"Batman II",
"The Tomorrow Knight",
"The second Dark Knight",
"The Dark Knight of Tomorrow",
"Batman Beyond"
],
"place-of-birth": "Gotham City, 25th Century",
"first-appearance": "Batman Beyond #1",
"publisher": "DC Comics",
"alignment": "good"
},
"appearance": {
"gender": "Male",
"race": "Human",
"height": [
"5'10",
"178 cm"
],
"weight": [
"170 lb",
"77 kg"
],
"eye-color": "Blue",
"hair-color": "Black"
},
"work": {
"occupation": "-",
"base": "21st Century Gotham City"
},
"connections": {
"group-affiliation": "Batman Family, Justice League Unlimited",
"relatives": "Bruce Wayne (biological father), Warren McGinnis (father, deceased), Mary McGinnis (mother), Matt McGinnis (brother)"
},
"image": {
"url": "https://www.superherodb.com/pictures2/portraits/10/100/10441.jpg"
}
},
{
"id": "70",
"name": "Batman",
"powerstats": {
"intelligence": "100",
"strength": "26",
"speed": "27",
"durability": "50",
"power": "47",
"combat": "100"
},
"biography": {
"full-name": "Bruce Wayne",
"alter-egos": "No alter egos found.",
"aliases": [
"Insider",
"Matches Malone"
],
"place-of-birth": "Crest Hill, Bristol Township; Gotham County",
"first-appearance": "Detective Comics #27",
"publisher": "DC Comics",
"alignment": "good"
},
"appearance": {
"gender": "Male",
"race": "Human",
"height": [
"6'2",
"188 cm"
],
"weight": [
"210 lb",
"95 kg"
],
"eye-color": "blue",
"hair-color": "black"
},
"work": {
"occupation": "Businessman",
"base": "Batcave, Stately Wayne Manor, Gotham City; Hall of Justice, Justice League Watchtower"
},
"connections": {
"group-affiliation": "Batman Family, Batman Incorporated, Justice League, Outsiders, Wayne Enterprises, Club of Heroes, formerly White Lantern Corps, Sinestro Corps",
"relatives": "Damian Wayne (son), Dick Grayson (adopted son), Tim Drake (adopted son), Jason Todd (adopted son), Cassandra Cain (adopted ward)\nMartha Wayne (mother, deceased), Thomas Wayne (father, deceased), Alfred Pennyworth (former guardian), Roderick Kane (grandfather, deceased), Elizabeth Kane (grandmother, deceased), Nathan Kane (uncle, deceased), Simon Hurt (ancestor), Wayne Family"
},
"image": {
"url": "https://www.superherodb.com/pictures2/portraits/10/100/639.jpg"
}
},
{
"id": "71",
"name": "Batman II",
"powerstats": {
"intelligence": "88",
"strength": "11",
"speed": "33",
"durability": "28",
"power": "36",
"combat": "100"
},
"biography": {
"full-name": "Dick Grayson",
"alter-egos": "Nightwing, Robin",
"aliases": [
"Dick Grayson"
],
"place-of-birth": "-",
"first-appearance": "-",
"publisher": "Nightwing",
"alignment": "good"
},
"appearance": {
"gender": "Male",
"race": "Human",
"height": [
"5'10",
"178 cm"
],
"weight": [
"175 lb",
"79 kg"
],
"eye-color": "Blue",
"hair-color": "Black"
},
"work": {
"occupation": "-",
"base": "Gotham City; formerly Bludhaven, New York City"
},
"connections": {
"group-affiliation": "Justice League Of America, Batman Family",
"relatives": "John Grayson (father, deceased), Mary Grayson (mother, deceased), Bruce Wayne / Batman (adoptive father), Damian Wayne / Robin (foster brother), Jason Todd / Red Hood (adoptive brother), Tim Drake / Red Robin (adoptive brother), Cassandra Cain / Batgirl IV (adoptive sister)"
},
"image": {
"url": "https://www.superherodb.com/pictures2/portraits/10/100/1496.jpg"
}
}
]
}
Мы сделали запрос и получили данные по Бэтмену. Теперь мы можем работать с ними в коде, как с обычным словарём. Для этого в Питоне есть встроенная библиотека json.
Подробнее про HTTP-запросы
Есть открытые API, которые не требуют аутентификации, например https://swapi.dev/documentation API по Звёздным войнам. Попробуй почитать документацию и разобраться, как выполнять запросы и получать данные.
Например, если почитать документацию, то можно узнать, что параметр search позволяет искать персонажа: https://swapi.dev/api/people/?search=r2
Давай изучим более подробно этот запрос:
HTTP 200 OK
Content-Type: application/json
Allow: GET, HEAD, OPTIONS
Перед тобой HTTP-заголовок, он есть в каждом запросе. Запрос состоит из заголовков и тела. Тело иногда может быть пустым.
Первая строка — это код ответа, 200 означает, что запрос прошел успешно. Это самый популярный код ответа. Наверняка ты знаешь про другой популярный код ответа: 404, который означает "Ресурс не найден". Обычно он приходит, когда мы ошиблись в вводе URL. Полный список можно посмотреть, например, здесь: https://ru.wikipedia.org/wiki/Список_кодов_состояния_HTTP
Далее идёт Content-Type, это тип данных, который пришёл к ответ на запрос. К примере выше тип был text/html, здесь же он уже отличается. Потому что данные пришли в формате JSON.
На третьей строке разрешенные методы. Про методы можно почитать здесь: https://ru.wikipedia.org/wiki/HTTP#Методы
Обычно мы применяем метод GET, когда хотим запросить какие-то данные, POST когда хотим передать какие-то данные. И так далее.
Пример работы с API: Twilio
На этот раз запросы будут происходить не напрямую к API, как мы это делали выше, а через специальную библиотеку-обертку. Многие сервисы их предоставляют и это очень удобно.
Зарегистрируйся на https://www.twilio.com, там нужно будет подтвердить свой email и номер телефона, это несложно.
Зайди в https://www.twilio.com/console и найди "Get my first Twilio phone number", чтобы получить номер, с которого будет уходить sms-сообщения. Это будет выглядеть как-то так:
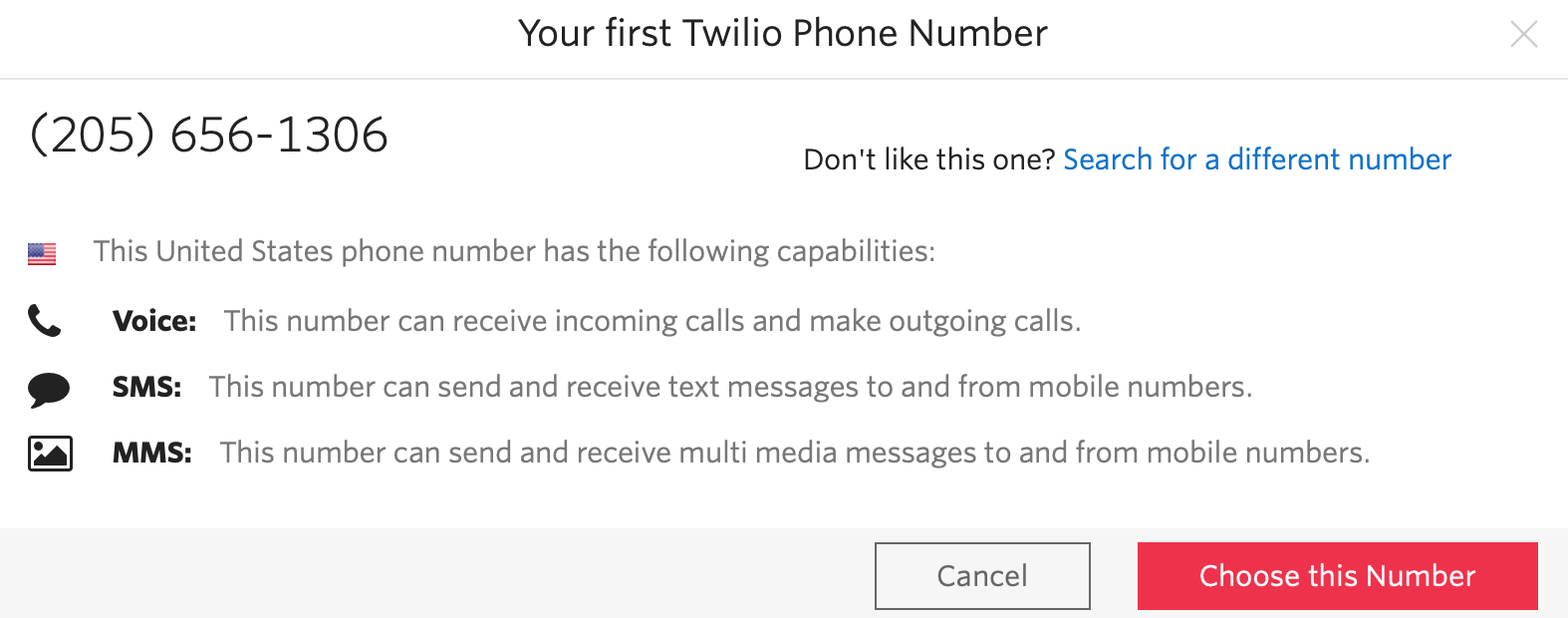
Соглашайся.
Пробный бесплатный период позволяет отправлять смс-ки только на свои подтвержденные номера, поэтому убедись, что здесь есть номер, на который ты хочешь отправлять собщения: https://www.twilio.com/console/phone-numbers/verified
Создай файл с именем send_sms.py:
import os
from twilio.rest import Client
from dotenv import load_dotenv
load_dotenv()
TWILIO_ACCOUNT_SID = os.getenv('TWILIO_ACCOUNT_SID')
TWILIO_AUTH_TOKEN = os.getenv('TWILIO_AUTH_TOKEN')
client = Client(TWILIO_ACCOUNT_SID, TWILIO_AUTH_TOKEN)
message = client.messages.create(
body='Привет!', # текст сообщения
from_='', # номер, который был получен
to='', # твой номер, на который придёт sms
)
print(message.sid)
Затем в этой же директории создай файл .env:
TWILIO_ACCOUNT_SID=
TWILIO_AUTH_TOKEN=
После знака "=" скопируй SID и AUTH_TOKEN из https://www.twilio.com/console.
Токен — это аналог пароля, уникальная комбинация символов, которая дает тебе доступ к API. Это похоже на пропуск, тебе нужно каждый раз посылать токен с каждый запросом.
Зачем нужен файл .env? В нём мы обычно храним секретные данные, в данном случае это наш номер аккаунта и токен для доступа. Если кто-то их узнает, то он сможет отправлять сообщения от твоего имени, это всё равно что отдать свой пароль. А ещё наш код будет храниться в репозитории, поэтому в нём никогда не должно быть секретных данных. Метод .getenv из модуля os достает эти данные из файла .env, или из переменных окружения, если такой файл отсутствует.
Выполни установку двух необходимых пакетов:
pip3 install twilio python-dotenv
Теперь добавь в код необходимые номера телефонов (там комментариями прописано) и можешь запускать!
Обработка исключений
Часто бывает так, что мы ждём какую-то внештатную ситуацию и знаем, как на неё реагировать. Например, мы делаем запрос к сервису API, а то вдруг оказался недоступным, программа упадёт с ошибкой. Или мы запрашиваем список юзернеймов всех студентов из чатика python101, а у пары студентов отсутствует юзернейм. Программа упадёт с ошибкой. И так далее.
В случае, когда мы хотим перестраховаться или знаем, что что-то может пойти не так, мы должны использовать обработку исключений: https://docs.python.org/3/tutorial/errors.html
Если проще, то это просто конструкция вида:
try:
hpmor_book = open('hpmor.txt') # какой-то код
except FileNotFoundError:
# код-который-выполнится-если-такого-файла-нет
finally: # необязательный блок
# код-который-выполнится-в-любом-случае
Мы ожидаем, что такого файла может не существовать и можем заранее прописать, как на это реагировать. В случае со студентами в Телеграме, можно, например, прописывать -пусто- или что-то ещё.
Исключения полезны при работе с API, потому что позволяют проверить, успешно ли отработал запрос. В случае, если нет, response.raise_for_status выкинет исключение requests.exceptions.HTTPError, которое можно как-то обработать.
Логирование
У тех, на кого ругался строгий линтер WPS, возникал вопрос "А почему он запрещает мне использовать функцию print()?!"
Причина кроется в том, что обычно программы запущены на сервере и доступ к стандартному выводу не всегда имеется. Ну и сама концепция использования принтов для отладки считается плохим тоном. Есть крутая альтернатива: логи.
Логи — это те же самые сообщения через print(), только они могут иметь уровень важности (один из пяти), метку времени (в какое время произошло событие) и ещё много чего полезного. Например, логи можно записывать в файл, чтобы потом посмотреть.
Документация доступна по адресу: https://docs.python.org/3/library/logging.html
Для того, чтобы использовать логи, нужно импортировать модуль logging.
Как уже было сказано выше, существует пять уровней логирования, по степени важности:
logging.debug('Сообщение для отладки')
Уровень DEBUG это самый не важный уровень, им пользуются сами разработчики для того, чтобы вывести какую-то отладочную информацию, которая ни на что не влияет.
logging.info('Друг появился online')
logging.info('SMS отправлено')
INFO — чуть более значимый уровень логирования, оповещает пользователя о каких-то событиях. Когда программа запущена, это позволяет получать информацию о том, что происходит.
WARNING — какое-то предупреждение, на которое стоит обратить внимание.
logging.warning('Не найден settings.json, использована заглушка')
ERROR — это уже серьезная ошибка, из-за которой программа не может нормально работать.
logging.error('Ошибка, сообщение не было отправлено')
CRITICAL — самый серьезный уровень, когда всё очень плохо и нужно срочно всё чинить!
logging.critical('МЫ ВСЁ УРОНИЛИ!!!11')
Логи можно настраивать под свои нужды, например: https://docs.python.org/3/library/logging.html#logrecord-attributes
Тут нужно использовать %-форматирование или метод .format, можно разобраться по примерам:
logging.basicConfig(format="%(levelname)s %(asctime)s %(message)s")
Добавляем эту строчку и теперь логи будут выводиться примерно так:
INFO 2020-11-09 02:55:51,102 Сообщение отправлено.
Можно настроить логи как угодно — чтобы выводилось имя файла, имя функции, в которой сработало и так далее. Можно записывать лог в файл и даже создавать свои собственные логгеры. Всё что для этого нужно — почитать документацию (ссылка была выше).
Что дальше?
Первое знакомство с API закончилось. Пройдемся ещё раз по основным тезисам.
API это интерфейс для программного взаимодействия с каким-то сервисом.
REST API — один из принципов построения API, стандарт, по которому общаются разные сервисы в интернете. Он работает поверх HTTP, используя HTTP-методы для общения.
HTTP-методы выступают в роли глаголов, URL выступают в роли существительных, параметры выполняют вспомогательную роль. Например, мы делаем запрос GET https://swapi.dev/api/people/?search=r2 — тут у нас GET (англ. "получить") глагол, people (англ. "люди"), и search ("поиск") по R2 — начальные символы робота R2D2. Запрос отработает и вернет нам информацию о роботе R2D2 из Вселенной StarWars.
Запросы можно делать как напрямую к API через библиотеку requests, так и используя (если они есть) библиотеки, которые делают это за тебя.
Также стоит упомянуть о бесплатной удобной программке Postman, которая позволяет совершать запросы к API: https://www.postman.com/product/api-client/
Практика
Подготовка
Скачай Postman и научись с его помощью делать запросы к сервису https://swapi.dev/documentation. Исследуй людей и планеты.
Сделай то же самое с помощью библиотеки requests. Изучи документацию: https://requests.readthedocs.io/en/latest/user/quickstart/
Отправь себе SMS с помощью сервиса Twilio с произвольным текстом.
Гугли все незнакомые слова и термины, задавай вопросы в чат.
Задание 1
Напиши скрипт для мониторинга доступности произвольного сервиса. В случае, если сервис становится недоступен, скрипт отправляет SMS-сообщение на твой номер. Сервисом может быть любой сайт или сервер (даже наш учебный). Опрашивай сервис каждые 60 секунд.
Позаботься о том, чтобы не хранить в репозитории личные данные.
Настрой хорошее логирование и записывай логи в файл.
Попробуем формат peer-review: выполняешь задание, грамотно оформляешь в публичном репозитории (лучше перечитай материал из второй недели) и скидываешь ссылку в чат.
Каждый сможет поревьюить чужие работы — либо написать замечания в чате, либо кинуть Pull Request с исправлениями, которые можно принять.
Задание 2 (необязательное)
У ВКонтакте очень плохой API, но тем не менее. :)
Напиши программку, которая мониторит онлайн-статус друга и посылает тебе SMS, когда друг появляется онлайн. Запросы к ВК API можно делать напрямую, а можно найти специальную библиотеку, как это было в случае с Twilio. На твой выбор.
Что потребуется:
Зарегаться в ВК (если ещё нет)
Добавить в друзья человека, который частенько бывает онлайн
Получить токен: https://vk.com/dev/
Найти нужный метод для получения статуса: https://vk.com/dev/methods
Написать пару функций для мониторинга и отправки SMS-сообщения
Логирование, обработка исключений, правильно оформленный репозиторий — вот это всё.