Основы Python
Интро
Почему Python? Питон или Пайтон? Обратимся к истории создания.
Язык программирования Python назван его создателем в честь британского комедийного шоу "Летающий цирк Монти Пайтона" (можешь посмотреть на youtube). С другой стороны, на логотипе мы видим змей и этот образ закрепился за языком. В курсе мы будем использовать слово "питон".
Это Гвидо ван Россум (Guido van Rossum), создатель питона.

Как всё началось. Гвидо работал над языком ABC в исследовательском университете в Нидерландах. Он хотел разработать максимально простой язык для программирования, на котором смогли бы писать люди, не имеющие специального технического образования.
Параллельно с работой над ABC в 1989 году Гвидо начал свой хобби-проект Python, потому что ему нечем было заняться дома, пока офис был закрыт на рождественские праздники.
В 1994 вышла первая версия, Python 1.0 и началось активное развитие языка.
В 2000 году вышла вторая версия, Python 2.0 и была утверждена концепция PEP (Python Enhancement Proposal, "предложение по улучшению Python"), суть PEP в том, что любой желающий может написать текст, который описывает какое-то улучшение в языке и отправить его на обсуждение комьюнити (сообществу тех, кто пользуется Питоном). Если предложение всем нравится, то Гвидо решает, принимать описанные изменения или нет.
В 2008 вышла третья версия, Python 3.0, которую мы и будем использовать. Вторая версия официально не поддерживается с 2020 года и её можно встретить редко, а про первую уже все забыли.
Питон — это скриптовый язык общего назначения. Основной акцент сделан на читаемости кода и удобстве работы программиста.
Питон прекрасно подходит, когда нужно набросать прототип, запилить стартап или что-то по-быстренькому запрогать. Но это не значит, что его нельзя использовать для более масштабных проектов. Можно. Такие компании, как Google, Яндекс, Yahoo и даже NASA активно используют этот язык. На сегодняшний день он является одним из самых популярных (https://www.tiobe.com/tiobe-index/) и входит в тройку лидеров. Также Питон является стандартом в сфере машинного обучения и анализа данных.

Питон — интерпретируемый язык. Ты пишешь код (инструкции для интерпретатора), затем происходит процесс превращения этих инструкций в байткод, который выполняется в интерпретаторе Питона. Интерпретатор — это штука, которая переводит байткод в нули и единицы, понятные центральному процессору компьютера. То есть мы пишем приятный читаемый код на Питоне, он потом переводится в набор инструкций (байткод) для интерпретатора, а интерпретатор передает эти инструкции процессору. Поэтому для запуска кода на питоне нужен интерпретатор. В некоторых языках программирования (например, Си) это происходит иначе и процесс называется компиляцией. Компиляция полностью превращает весь твой код в машинный и выдает результат, который можно потом запустить напрямую. Не будем пока в это погружаться.
Теперь ещё про одно важное свойство языка — про типизацию. Питон — язык с динамической типизацией. Это значит, что проверка типов происходит в момент исполнения. Что значит для тебя примерно нифига... Но ничего, потом будет понятно.
Основные мысли этого урока — питон интерпретируемый язык, который выполняет команды построчно. Процесс исполнения команд называется интерпретацией. У питона динамическая типизация, поэтому проверка типов происходит в момент исполнения кода. Скорость и удобство разработки заложены в дизайн языка.
Главная цель этой недели — построить в твоей голове нейронные связи с основными концепциями и конструкциями языка. Не застревай сильно на теории, старайся как можно больше экспериментировать с полученными знаниями и пробовать делать что-то своё. На первом месте должна быть практика! Относись к теории, как к тому минимуму, без которого нельзя добраться до этой практики. Нужно немного почитать, познакомиться с базовыми понятиями, вооружиться документацией и вперёд!
Это похоже на то, как мы изучаем иностранный язык — сначала тратим какое-то время на грамматику и синтаксис, потом поднимается на уровень выше и думаем уже о том, ЧТО сказать, а не о том, КАК сказать. Очень важно размышлять о задаче, которую надо решить, а не о конструкциях языка. Сейчас нам нужно поскорее подняться на этот уровень.
Не гугли пока, потому что в интернете очень много инфы и ты пока не можешь отличить плохое от хорошего. Лучше задай вопрос в чате, если что-то непонятно. Читай только этот курс и официальную документацию, в ней всё есть.
Запуск интерактивного интерпретатора
В курсе мы будем пользоваться Python 3.9, поэтому убедись, что он у тебя установлен, открой VS Code, внизу у тебя должен быть терминал, и набери python3 -V, чтобы узнать версию интерпретатора:
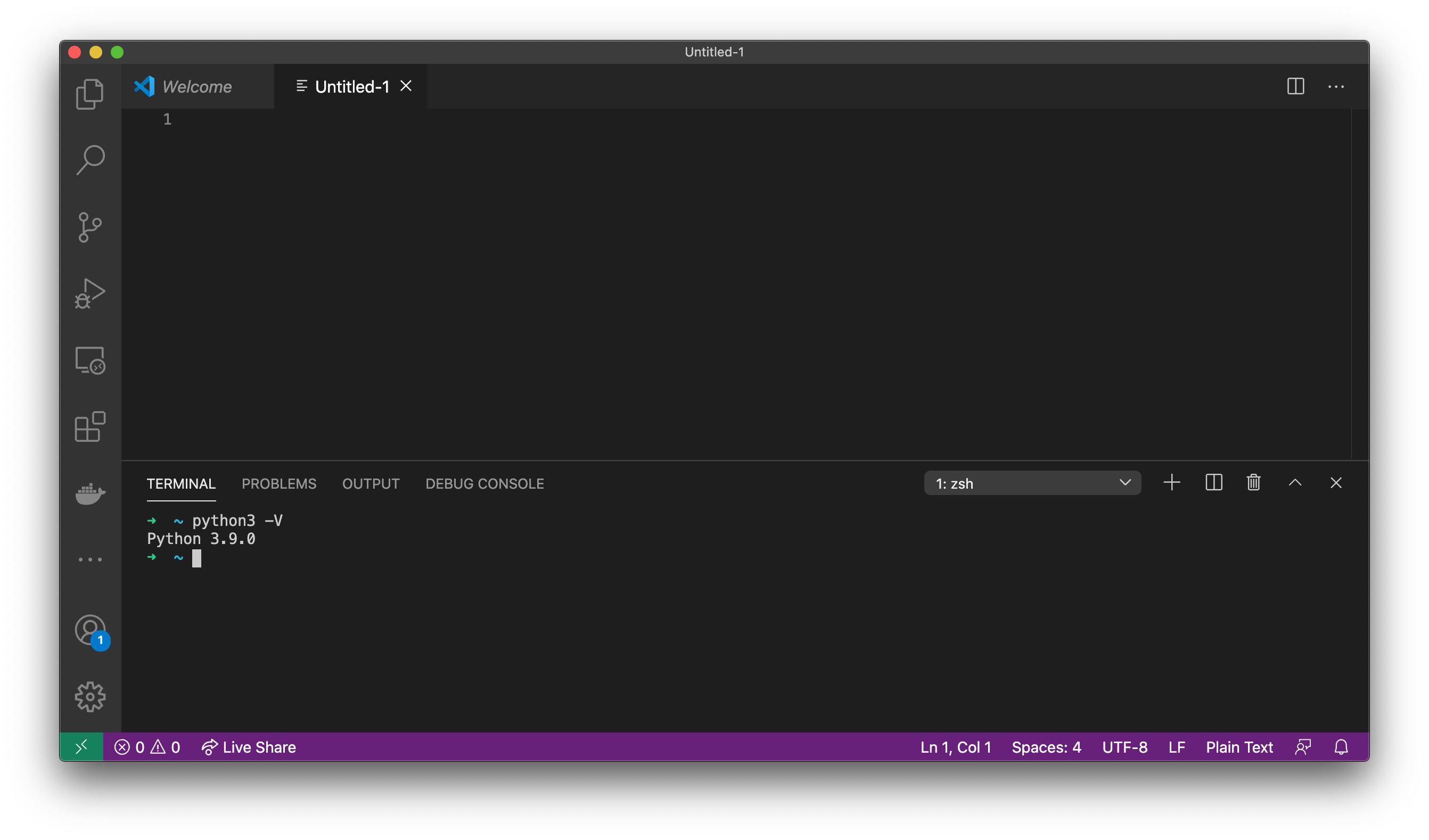
Если версия ниже, то установи последнюю версию: https://www.python.org/downloads/
Затем введи команду для запуска интерпретатора в режиме REPL: python3

Готово. Перед тобой интерактивный интерпретатор Питона и он будет выполнять команды по одной, возвращая результат. Все аналогично тому, как было в Баше. Это полезно, когда нужно быстро проверить какие-то гипотезы и увидеть результат, но не годится для написания кода. Код мы будем писать в редакторе в следующем уроке, а сейчас поработаем с некоторыми типами данных в Питоне. Так сказать, первое знакомство.
Тройная стрелочка — это приглашение интерпретатора ко вводу команд: >>> , как знак $ в Баше.
Чтобы выйти, набери quit() или exit() или сочетание клавиш Ctrl+D.
Итак, попробуй сложить два числа. Получилось?
>>> 17 + 6
23
Напиши exit() и иди дальше.
Запуск программ
Только что мы выполнили код "на лету" — интерпретатор сложил два числа и выдал результат.
В редакторе VS Code мы можем просто нажать зеленую стрелочку и он выполнит код, потому что знает, где лежит интерпретатор.
Также мы можем сохранить код в файле с расширением .py и передать его на вход интерпретатору: python3 [hello.py](http://hello.py).
Но мы можем пойти ещё дальше. Питон — такой же скриптовый язык, как и Баш. Поэтому мы можем сохранить наш файл hello без расширения, и указать первой строчкой путь до интерпретатора через шебанг:
#!/usr/bin/env python3
print('hello world')
Затем назначить его исполняемым: chmod +x hello и запускать напрямую. Можно даже переписать микро-проект srm на Питоне и он будет работать!
В курсе будем запускать код прямо в VS Code, используя горячие клавиши Ctrl+Enter, предварительно сохранив его нажатием Ctrl+S.
Основные типы данных
Когда мы программируем на питоне, мы всегда оперируем какими-то типами данных. Это могут быть простые типы: чуть раньше мы сложили два числа. Если мы хотим написать программу, которая складывает числа, этого может быть достаточно.
Но что, если мы захотим запрогать что-то более интересное, например, перенести список студентов этого курса в код, чтобы написать программу, которая будет что-то делать с этим списком? Например, посчитает количество студентов, упорядочит их по алфавиту, или будет поддерживать список в актуальном состоянии, убирая из него тех, кто выбыл из курса. Тут уже не обойтись без другой структуры данных — список.
Для решения разных задач существует множество типов данных. Более того, мы можем создавать собственные типы данных, когда нам не хватает встроенных.
Сейчас мы познакомимся с двумя основными типами данных и операторами, которые используются чаще всего. Это практический урок — все примеры надо выполнять в интерпретаторе, потом немного изменять их и смотреть что происходит. Не бойся экспериментировать!
Числа
Числовые типы данных представлены целыми числами (Integer), числами с плавающей точкой (Float) и комплексными числами (Complex). Третий тип тебе скорее всего не понадобится, поэтому рассмотрим первые два.
Ты уже пользовался функцией print(), которая выводит на экран все, что получает в скобки. С другими функциями принцип такой же — ты передаешь ей что-то в скобки, она с этим что-то делает и возвращает результат. Теперь познакомимся с функцией type(). Эта функция позволяет посмотреть на тип объекта.
Целые числа относятся к классуint. Например, число 3:
type(3)
# <class 'int'>
Это просто целые числа. Обычные числа. Положительные и отрицательные. Число может быть какой угодно длины, особо длинные числа для удобства можно записывать так: 1_000_000_000, это косметическая штука, чтобы не запутаться в нулях, значение будет все равно 1000000000.
Числа с плавающей точкой относятся к классуfloat. Например, 2.5:
type(2.5)
# <class 'float'>
Они же вещественные числа. Есть целая и дробная часть. То же самое для нуля: 0.0 и отрицательного -1.0.
При сложении двух целых чисел, как мы убедились выше, получается другое целое число. А что произойдёт, если сложить целое и вещественное число? Сделай это в репле и узнаешь.
Операторы
Оператор — это конструкция, которая что-то делает с операндами. Например, оператор сложения складывает то, что слева (первый операнд) с тем, что справа (второй операнд).
Арифметические операции
С числами можно выполнять арифметические операции:
2 + 2 сложение
2 - 2 вычитание
2 * 2 умножение
2 / 2 деление с остатком
Обрати внимание, что операция деления с остатком приводит число к типу float
3 // 2 деление без остатка, целочисленное деление, тип остается int, остаток отбрасывается
3 % 2 остаток от деления, здесь наоборот — остается только остаток
2 ** 4 возведение в степень
При операциях с целыми и вещественными числами, результат по умолчанию становится float. Например, проверь, что будет если сложить int и float: 1 + 2.0
Порядок операций, приоритет. Всё как в школьной математике — 10 + 5 * 2. Сначала будет выполнено умножение, потом сложение. Если нужно задать нужный приоритет — используй скобки: (10 + 5) * 2
Делить на ноль нельзя. 🤷♂️
Порядок операций
Как все помнят (надеюсь) со школы, некоторые математические вычисления имеют приоритет: 2 + 2 * 2 будет равняться шести, потому что операция умножения выполняется первой. Если ты хочешь изменить дефолтный порядок, то используй скобки — (2 + 2) * 2.
Функции для работы с числами
С помощью функции round() можно округлять числа до какого-то количества знаков:
round(2.5) # результат равен 2
Функция int() конвертирует в целое число все, что можно конвертировать в целое число:
int(2.5) # 2 дробная часть теряется
int('2') # из строки 2 в число 2
Функция float() , как нетрудно догадаться, конвертирует в число с плавающей точкой:
float(2) # 2.0
Потрать 10-15 минут на то, чтобы поэкспериментировать с числами в интерпретаторе: складывай, умножай, округляй, сравнивай.
Строки
Строки в питоне представляют собой неизменяемую последовательность символов. Таким образом, строка может быть представлена одним символом, большим количеством символов (слово, предложение, абзац текста) и даже не содержать ни одного символа (быть пустой строкой).
Строки заключают в кавычки. Кавычки могут быть двойными или одинарными. Между ними нет разницы, нужно просто определиться, какие больше нравятся и использовать только их. Ещё есть тройные кавычки, которые также могут быть двойными или одинарными. Их удобно использовать для большого количества строк текста.
Если нужно использовать кавычки внутри самой строки, то используй другие кавычки. Можно экранировать любые кавычки с помощью символа \. Можно экранировать экранирующий символ с помощью префикса r(это называется "сырые строки" (raw strings):
print('можно использовать двойные "кавычки" внутри')
print('или можно \'вот\' так')
print(r'когда нужно \ оставить \ всё \ как \есть')
Ещё примеры:
print("Обратный слэш также работает за пределами строк," \
"когда нужно разбить очень длинную строку на экране")
print("""
аналогично можно применять ТРОЙНЫЕ КАВЫЧКИ
когда нужно написать
какой-то
длинный
текст
""")
Строки можно складывать (конкатенировать). Тогда они объединяются в одну строку. И даже умножать, тогда они повторяются:
print('hello' + ' world') # 'hello world'
print('hello' * 3) # hellohellohello
Пустая строка обозначается ''.
Строка имеет тип str:
type('hello')
# <class 'str'>
Преобразование в строку осуществляется с помощью функции str():
str(42) # преобразовали число 42 в строку '42'
Важно понимать, что '42' это уже не число, а строка. И мы не сможем производить с ним арифметические операции.
Строки неизменяемые. Когда ты что-то делаешь со строкой, она полностью перезаписывается.
У строки есть длина, узнать длину можно с помощью функции len():
len('hello') # 5
Индексы
К символам строки, как к любым последовательностям, можно обращаться по индексу. Индекс начинается С НУЛЯ.
hello[0] # h
hello[3] # l
Кроме обращения к конкретному символу , можно также делать срезы символов, если указать два индекса, "от" и "до":
[1:3] слева указан индекс, с которого начинается срез справа последний индекс. Есть ещё шаг, это третий индекс, но он необязательный. Если указать шаг, то срез пойдёт циклически, просто попробуй это сделать в интерпретаторе — 'какая-то строка, из которой нужно сделать срез'[1:3:2]
Если не указываем какой-то из индексов, то считается что это ноль.
[:3] с нулевого индекса до третьего (не включительно)
[3:] с третьего до последнего
[2:5] со второго по пятый (не включительно)
[0:4:2] с нулевого по четвертый, каждый второй
Примерчики:
text = 'Добро пожаловать на первый поток Курса!'
text[:14] # 'Добро пожалова'
text[2:14] # 'бро пожалова'
text[33:41] # 'Курса!'
text[::2] # 'Дбопжлвт апры оо ус!' (каждый второй символ)
Форматирование строк
Существует несколько способов форматирования строк в Питоне, начиная от простой конкатенации, когда мы просто склеиваем что-то операцией сложения:
name = 'Дима'
age = 26
print('Меня зовут ' + name + '. Мне ' + str(age) + ' лет.')
Бррр. Никогда так не делайте!
Следующий способ пришёл в Питон из языка Си:
name = 'Дима'
age = 26
print('Меня зовут %s. Мне %d лет.' % (name, age))
Ну... Кажется, этот способ будет привычен тем, что писал раньше на Си
Следующий способ — метод .format()
name = 'Дима'
age = 26
print('Меня зовут {}. Мне {} лет.'.format(name, age))
Используется чаще всего, многим нравится.
И наконец, самый новый, самый быстрый и самый гибкий способ форматирования, который пришёл с версии 3.6 — f-строки:
name = 'Дима'
age = 26
print(f'Меня зовут {name} Мне {age} лет.')
Этот способ похож на предыдущий, но он круче, рекомендуется использовать его, но помни, что этот способ поддерживается только в версии Python 3.6+
Методы строк
Методы — это функции, привязанные к какому-то одному типу данных. Вызываются через точку: .upper()
У строк есть свои методы. Например, метод 'hello'.upper() изменит буквы на заглавные: HELLO.
Метод .endswith проверит, оканчивается ли строка на переданные символы и вернёт True или False:
filename.endswith('.py')
# проверит переменную filename на окончание
Метод .lower вернёт копию строки, преобразованному к нижнему регистру:
hello = 'Hello World'.lower()
print(hello) # hello world
Чтобы посмотреть все методы строк, набери в репле dir(str):
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'removeprefix', 'removesuffix', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
Чтобы получить справку по конкретному методу, воспользуйся в репле функцией help(), например help(str.find):
find(...)
S.find(sub[, start[, end]]) -> int
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation.
Return -1 on failure.
Полный список методов строк лежит здесь: https://docs.python.org/3/library/stdtypes.html#string-methods
Переменные
Переменные — основные элементы любых компьютерных программ. Переменные нужны для обращения к объектам: мы создаем какую-то штуку и даем ей имя, чтобы использовать дальше в коде. Можно представить переменную как стикер, который мы наклеиваем на объект, чтобы потом быстро его находить.
Например, мы
В Питоне объект — это основная сущность. У объекта есть три важных свойства — уникальный идентификатор (местонахождение объекта в памяти), тип данных (например, строка или число) и конкретное значение этого типа данных (например, 'привет' или 42).
Таким образом, переменные являются ссылками на область памяти, в которой хранится объект.
Представь, что ты создаешь какой-то набор данных, например список дней недели и присваиваешь ему имя. Этот список хранится в оперативной памяти компьютера в момент запуска проей программы. Представим оперативную память компьютера как огромный шкаф. Каждый объект хранится под каким-то своим номером — это идентификатор объекта, он выглядит как целое число — 4352564576. Получить номер этого идентификатора можно с помощью функции id():
id(weekdays) # 4352564576
Создай в репле переменную my_planet и запиши в нее имя планеты.
my_planet = 'Земля'
# записали имя планеты в переменную my_planet
Оператор присваивания = (да, это "равно"). Он берёт то, что справа от него и присваивает этому такое имя, которое слева от него. Мы создали объект строкового типа со значением 'Земля' и связали его с переменной my_planet!
А теперь проведи эксперимент в репле. Посмотри тип объекта с помощью функции type()и его идентификатор с помощью id(). Теперь создай ещё одну переменную и соедини её с первой: blue planet = my_planet. Проверь идентификаторы объекта, на который ссылается каждая переменная.
Именование переменных (нейминг)
Итак, переменная — это уникальный идентификатор области памяти, в которой хранится объект. Нужно очень внимательно относиться к именам переменных. Это важно, потому что твой код будут читать другие программисты и ты в будущем. Чаще мы читаем код, чем пишем. Пишем код один раз, а читаем (редактируем) очень много раз. А в питоне это важно вдвойне, потому что удобство чтения кода — это одна из ключевых особенностей языка. "Readability counts", как говорится в "дзене питона".
Имя переменной может состоять из символов, нижнего подчеркивания и цифры, но не может начинаться с цифры. Вообще можно использовать любые символы, но лучше использовать английский язык, иначе другие программисты могут тебя не понять.
Забавный факт: если показать тебе твой код через пару месяцев, то ты не вспомнишь авторство. Поэтому позаботься о себе из будущего, пожалуйста.
Записывать переменные можно в разных стилях, это называется нотацией. Бывает верблюжья нотация (camelCase), змеиная(snake_case), шашлычная(kebab-case), кричащая(SCREAMING_CASE) и так далее. Обычно каждый язык программирования придерживается какого-то своего стиля. В питоне переменные принято оформлять, как нетрудно догадаться, в снэйк_кейсе, то есть слова разделены нижним подчеркиванием и пишутся с маленькой буквы.
Переменная должна иметь смысл. Из имени переменной должно быть понятно, что лежит внутри. Если глядя на переменную не понимаешь, что в ней лежит, значит надо изменить имя. Не нужно использовать слишком общие имена, но и не нужно слишком подробно описывать, максимум 3 слова, разделенных нижним подчеркиванием. Если слово слишком длинное, то можно его сократить каким-нибудь очевидным образом, чтобы было понятно. Но лучше не сокращать без необходимости.
PEP8 (соглашение об именовании) приводит рекомендации по называнию переменных (https://www.python.org/dev/peps/pep-0008/#naming-conventions), почитай этот документ, мы будем часто к нему возвращаться.
Питон позволяет нам использовать любые символы, даже называть переменные по-русски, но делать так не нужно, translitom tozhe ne nuzho, a to drugie programmisty mogut tebya pobit. Только английский. Это стандарт.
Переменная должна быть существительным.
Теперь про семантику названий:
Если в переменной лежат просто числа, строки, отдельные объекты — то называем переменную существительным в единственном числе:
username = 'Anastasia'
city = 'Amsterdam'
age = 25
Количество — "что-то" + _count. Например, если мы храним в переменной количество студентов, то следует назвать ее students_count:
click_count = 15 # храним здесь количество кликов
Коллекции (о них через пару уроков) — существительное во множественном числе: users, students но лучше пояснять, че за юзерс, какие именно пользователи:
python101_students = ['Rus', 'Max', 'Andy', 'Kate', 'Sofi']
Общие значения:
Строки — если это просто какая-то строка, то можно text, sentence, word
Числа — number
Булевы значения (да или нет). is_admin, has_premium
Константы:
Во многих языках программирования есть константы как отдельный тип данных, в Питоне ткого нет. В питоне есть только соглашение, если ты назвал переменную БОЛЬШИМИ БУКВАМИ (SCREAMING_CASE), это значит, что эту переменную нельзя менять, это константа, не трогай её. Положил и пусть лежит. Обычно константы объявляют в самом начале программы (модуля) и потом только используют. Программа не должна этого делать, константы задаются вручную и не изменяются в процессе жизни программы.
Односимвольные имена:
Старайся никогда не использовать односимвольные имена, потому что они не несут смысловой нагрузки, особенно l (потому что непонятно, что строчная l (эл) или заглавная I (ай)), O (что это - "0" (оу) или "о" (ноль)).
Если нужны парные переменные для чего-либо, то нужно использовать консистентные антонимы — begin/end, open/close.
Нельзя использовать зарезервированные (ключевые) слова или имена встроенных типов данных, которые закреплены в питоне за чем-то другим, например and, for, class. Если прям совсем никак, то можно так: class_
Полный список зарезервированных слов:
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
При итерациях (о них в следующем уроке) лучше тоже явно указывать элемент:
for i in ... что такое i? непонятно!
Плохие примеры названий переменных: result, var, data, obj, item, key, value. Не result, а users_online. data — что за дата? object — в питоне всё обджект! item - хуитем!
Когда нужно определить временную переменную и подчеркнуть то, что она не несет в себе никакого смысла, используй вместо переменной символ нижнего подчеркивания _
Подытожим: к именованию переменных нужно подходить серьезно. Если при первом взгляде на переменную сложно понять, что внутри, значит у нее плохое имя. Есть общепринятые рекомендации, которые помогут с этим.
Правильное именование приходит с опытом, но только если к этому осознанно стремиться. Есть один хак. Представь, что ты открываешь свой код проекта спустя какое-то время и хочешь что-то допилить, ты ищешь переменную, чтобы изменить, конечно ты не помнишь точно как она называется, но у тебя в голове есть какое-то представление о том, как она должна называться, находишь, и удивляешься, что как-то неочевидно. Так вот, не поленись и измени имя на то, что было у тебя в голове. Скорее всего это имя более очевидно. Ещё раз — если ты ищешь переменную с одним именем, а находишь с другим, то скорее всего лучше переименовать имя на то, которое искал. В следующий раз ты снова будешь искать по такому же имени и сразу найдешь. Скорее всего то, что сразу приходит в голову — более очевидное. Текстовый редактор поможет изменить сразу все переменные во всем коде, чтобы ничего не пропустить. Спроси в чате, как это сделать.
Запись и чтение данных
Как выводить данные на экран ты уже знаешь — функция print() выводит данные на стандартный поток вывода.
Чтобы получить данные от пользователя со стандартного потока ввода, используй функцию input(). Она выводит на экран текст, который ты передаешь ей в качестве аргумента (текст подсказки, что ожидается какой-то ввод данных) и ждёт, пока пользователь что-то введёт и нажмёт Enter. Аналог команды read в баше.
first_name = input('Как тебя зовут?') # запишет имя в переменную first_name
Значение, переданное в функцию input() будет строкой. Важно помнить об этом, когда ты ожидаешь от пользователя какие-то числа. В этом случае нужно преобразовать строку в число.
Комментарии
Если максимально просто, то комментарии в коде — это всё, что находится справа от символа "решетка". Комментарии игнорируются интерпретатором. Это просто какой-то текст, который несет информацию. Иногда комментарии удобно использовать, чтобы временно отключить какой-то блок кода, но нужно не забывать вернуть потом обратно или удалить их.
print('hi') # это комментарий, он игнорируется интерпретатором
# print('этот принт не будет выполнен')
С комментариями нужно соблюдать осторожность. Хороший код не нужно комментирвоать, потому что и так понятно, что он делает. Скорее всего, если ты хочешь написать комментарий в коде и описать что он делает, то нужно переписать этот код. Нооо нет) на самом деле очень часто есть неочевидное поведение и нужны комменты.
Комментарий должен объяснять какие-то неочевидные вещи, отвечая при этом на вопрос "зачем", потому что на вопросы "что" и "как" отвечает сам код.
PEP8
PEP8 — это рекомендации по оформлению кода, принятые по умолчанию. В компании
Нужны для того, чтобы все писали код в одном стиле и всем было удобно читать такой код. PEP8 нужно полностью изучить и всегда его придерживаться, если в компании нет своего стандарта: https://www.python.org/dev/peps/pep-0008/
У компании Google, например, он есть: https://google.github.io/styleguide/pyguide.html
К счастью, существуют так называемые линтеры, которые следят за качеством и стилем кода.
Линтеры
Чтобы поддерживать стиль кода в порядке, существуют специальные плагины — линтеры и форматтеры. Некоторые из них проверяют код только на PEP8, некоторые проверяют только стиль, или только типы, или только отступы:
- проверяют только стиль (flake8, black, autoformatter, linter)
- стиль + семантика (pylint)
- type checking (mypy, pyro)
Что круто, когда используешь линтер — он тебя учит писать красивый код, дисциплинирует. В курсе мы будем пользоваться самым строгим линтером WPS, он работает поверх Flake8.
Чтобы настроить проверку в VS Code, нажми Ctrl+Shift+P, и в выпадающем списке начни вводить "Python...":

Нажми Select Linter и выбери flake8, затем аналогичным образом нажми Enable Lintingи убедись, что он включен ("on").
Теперь переместись в Терминал и выполни команду
pip3 install wemake-python-styleguide
Эта команда установит плагин WPS для Flake8.
Теперь каждый раз, когда ты будешь сохранять код (нажимать Ctrl+S), во вкладке Problems линтер будет подсказывать, что не так с твоим кодом:
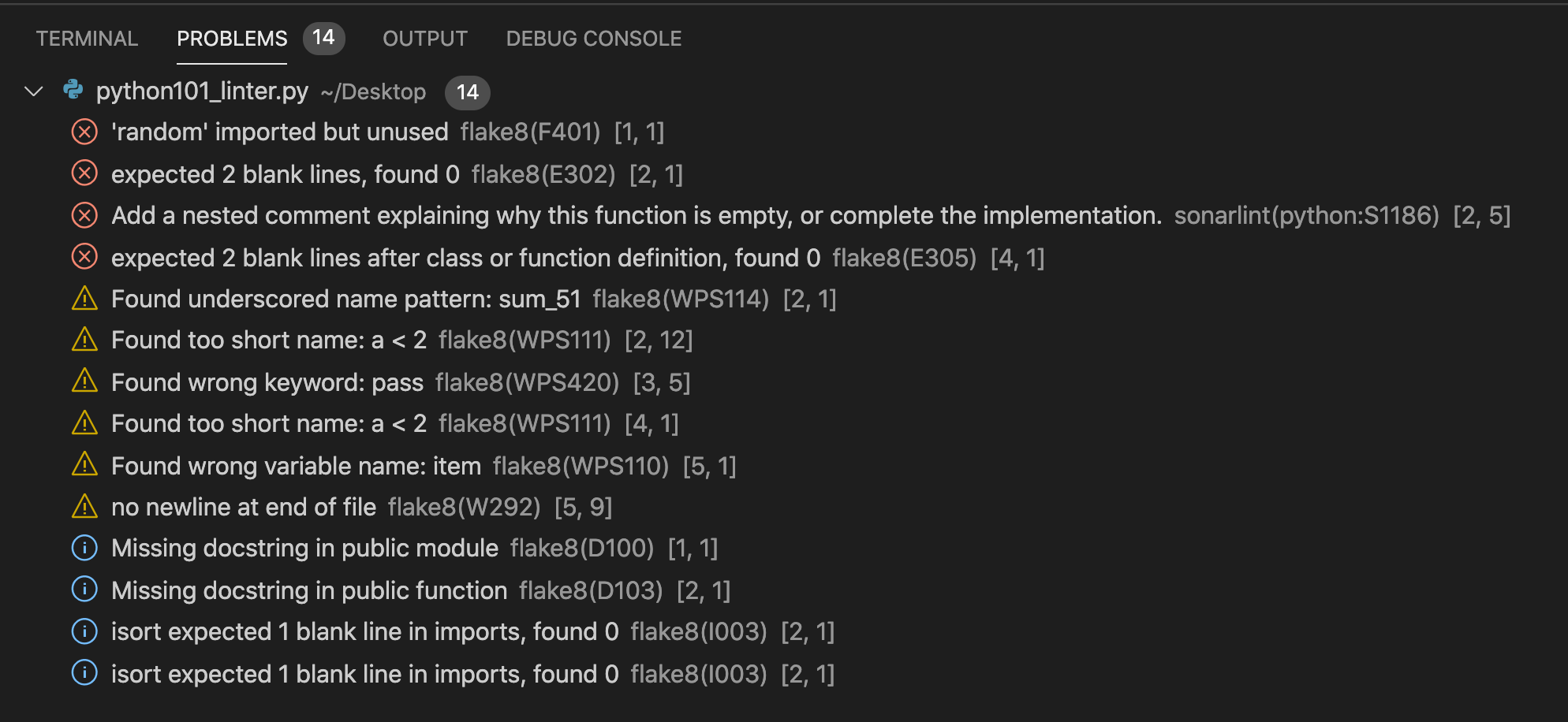
Если хочется отключить какую-то проверку, то можно настроить Flake8 для этого: https://flake8.pycqa.org/en/latest/user/configuration.html
Чтобы сказать линтеру "не проверяй эту строчку" просто добавь в конце строки комментарий # noqa ("no quality assurance").
Можно пойти ещё дальше и настроить Flake8 так, чтобы он не позволял делать коммит, пока есть какие-то неразрешенные проблемы с помощью механизма pre-commit hook'ов, почитать про это можно здесь: https://flake8.pycqa.org/en/latest/user/using-hooks.html
Пре-коммит хуки полезны, например, при командной разработке, чтобы все писали код в едином стиле и радовались жизни.